
티스토리 뷰
[1] 판다스 간단 소개
Pandas는 데이터 처리를 해주는 라이브러리 입니다.
대부분의 데이터 셋는 2차원 데이터 (행과 열로 구성된 = 엑셀 시트 같은)로 구성되어있는데
판다스는 2차원 데이터를 효율적으로 가공/처리할 수 있는 다양한 기능을 제공한다고 하네요-!
제가 읽고 있는 책(파이썬 머신러닝 완벽 가이드 - 권철민님) 에서는 판다스 기능만 설명해도 책 한권 분량이 될 정도라고 하십니다..😮
책에서 나온 재밌는 것들을 한번 해보고 정리하고 싶어서 살짝 판다스를 맛보겠습니다=!!
[2] 캐글에서 데이터 다운받기
책에서는 타이타닉 데이터를 썼는데, 캐글의 데이터 셋을 보다가 재밌을 것 같아서 골랐어요-! 유투브 트렌드 분석!
www.kaggle.com/datasnaek/youtube-new?select=KRvideos.csv
Trending YouTube Video Statistics
Daily statistics for trending YouTube videos
www.kaggle.com
나라별로 있는데 한국 데이터 쓸게요

캐글 사이트는 이렇게 칼럼에 대한 설명이랑
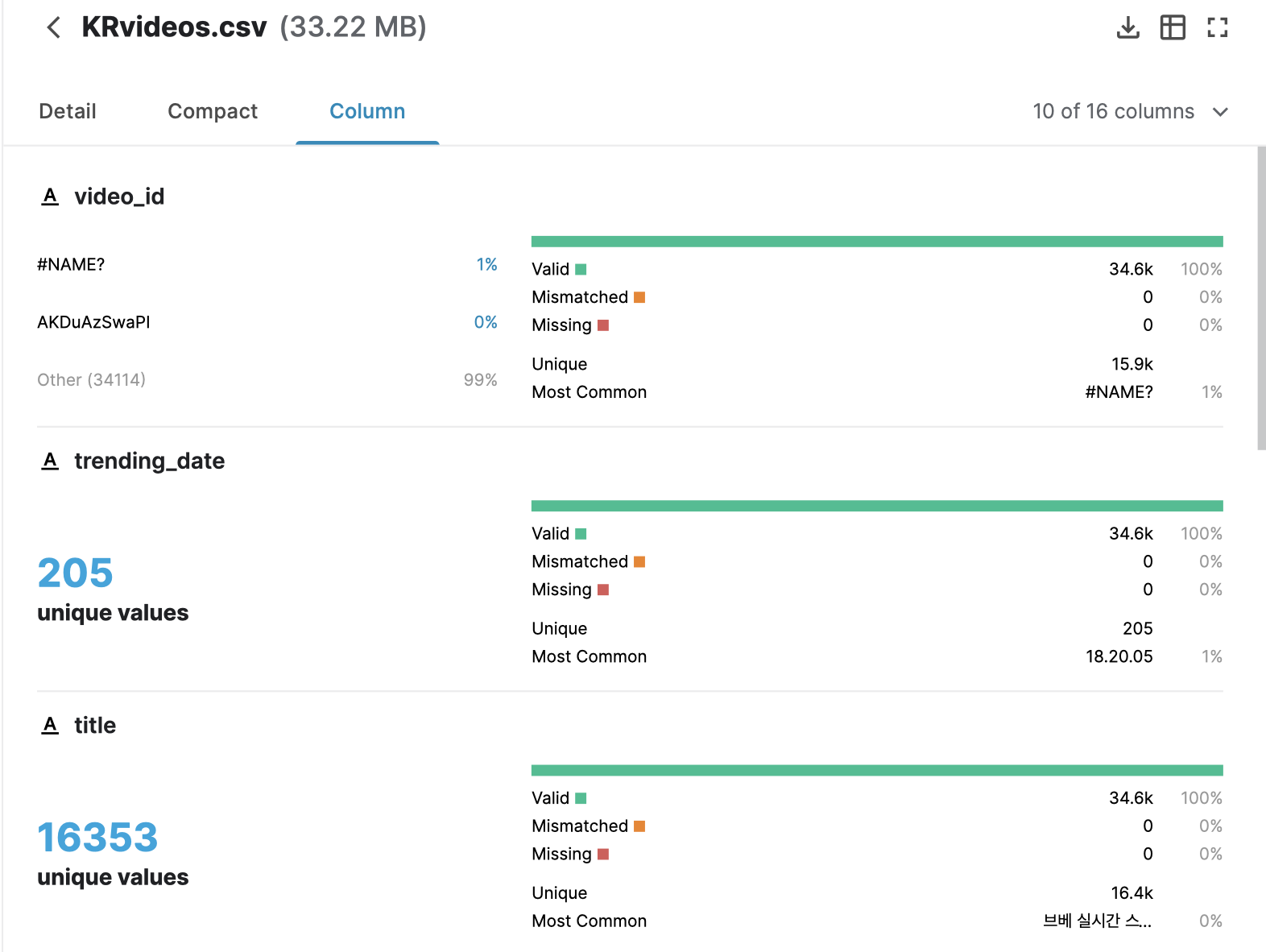
어떤 데이터들이 각 칼럼에 들어가는지를 데이터셋을 다운안받고도 프리뷰로 보여줘서 너무 좋은 것 같더라구요-!!
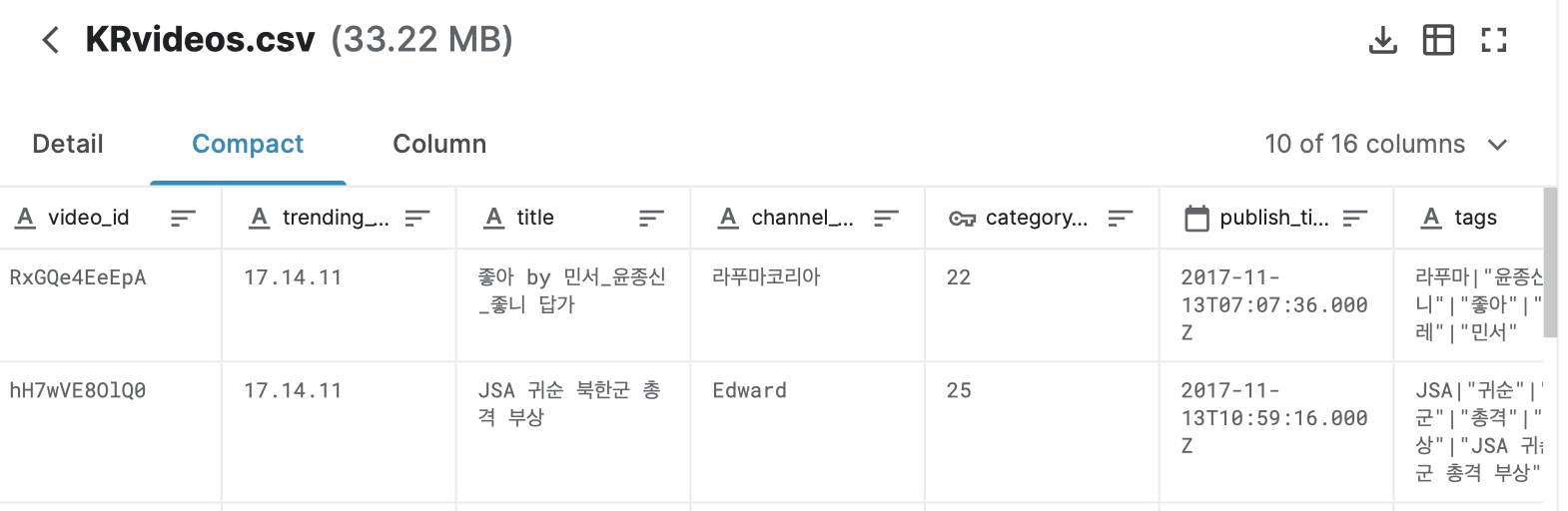
그럼 다운받은 csv파일을 아톰에디터로 열어보겠습니다-!!
맨 윗줄에는 칼럼명이 나열되어있고 그 밑으로 데이터가 쭉있네요

이 데이터들을 판다스를 이용하여 살펴보겠습니다.
[3] Pandas를 import하고 데이터를 읽어보기
저는 ml_env라는 가상환경을 만들고 pandas를 설치해주었습니다.
pip install pandas
read_csv('filepath', sep='\t') 함수를 이용하여 csv를 읽어올 수 있는데요
filepath는 csv 파일이 있는 파일패스,
sep는 seperator의 약자로 구분문자인데 디폴트값이 콤마 (sep=',') 라고 합니다.
저희의 csv는 콤마로 데이터들이 나눠져있으므로 sep설정은 안해주고
filepath설정만 해주었습니다.
그리고 한글데이터를 담고있는 csv라서 List of Python standard encodings 인코딩표를 보고 encoding = '어떤 값' 를 따로 해줘야하는데
engine = 'python' 하면 encoding 설정안해줘도 된다고 하더라구요...!
import pandas as pd
dataFrame = pd.read_csv('/Users/eunjin/Desktop/KRvideos.csv', engine='python')
dataFrame.head(3)
csv를 읽어서 데이터를 앞에서부터 세개만 가져오도록 해봅시다..!

그리고 dataFrame이라고 변수명을 정한이유는 csv읽어오면 DataFrame 타입이여서...! (2차원 데이터를 dataframe이라고 합니다)

[4] 데이터 특성 살펴보기
1) 데이터의 크기
dataFrame.shape
dataFrame.shape 로 데이터의 크기를 출력해볼 수 있습니다.

34567개의 로우와 16개의 칼럼으로 이뤄진 데이터 입니다.
2) 칼럼 정보
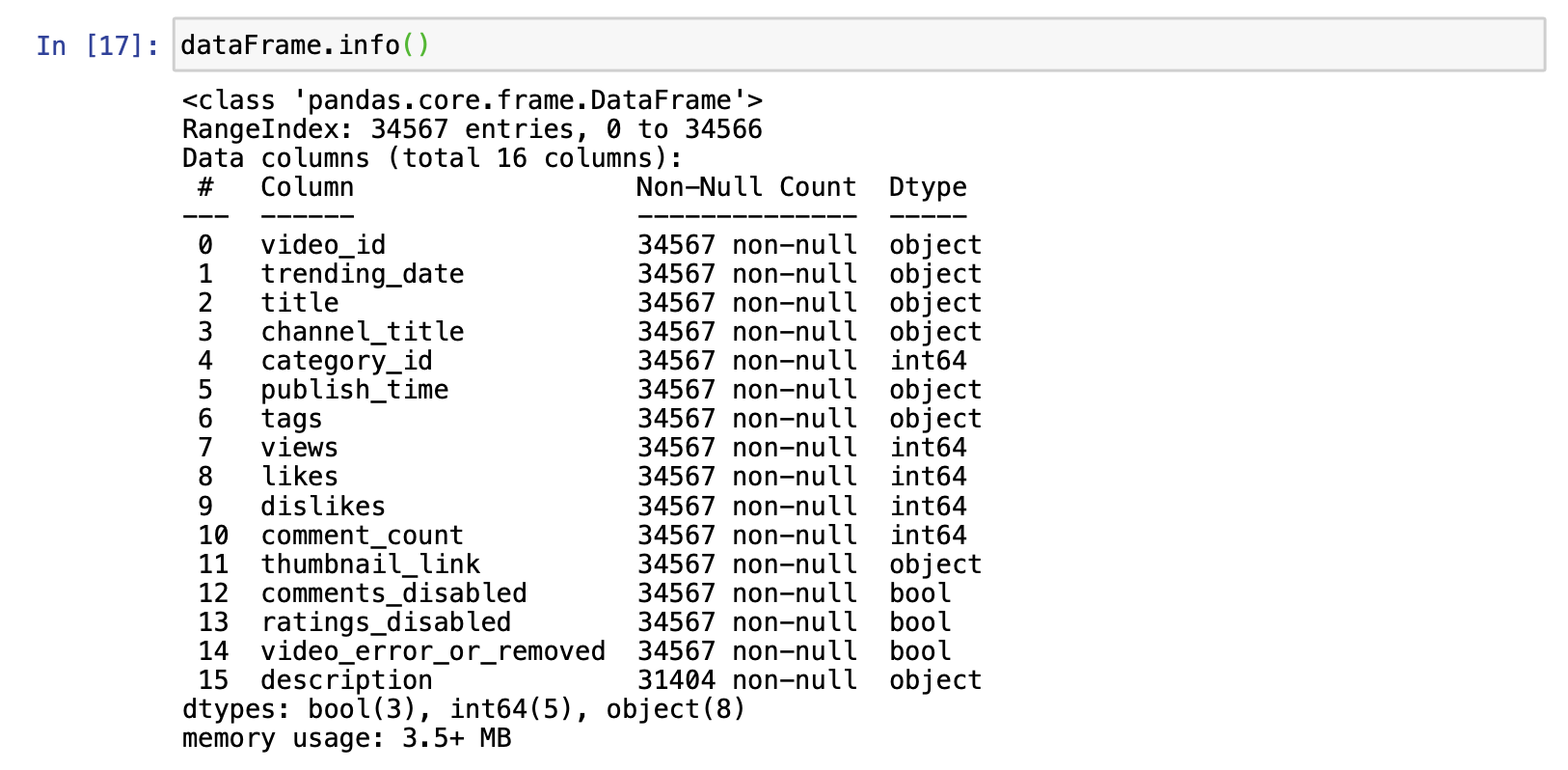
dataFrame.info()
dataFrame.info()로 칼럼 정보들을 알 수 있습니다.
- 어떤 칼럼들이 있는지
- 각 칼럼에서 non-null인 데이터의 개수는 몇개인지,
- 각 칼럼의 타입은 뭔지
3) 데이터의 분포도
dataFrame.describe()
dataFrame.describe()로 대략적인 데이터의 분포도를 볼 수 있습니다.
- count: Not Null인 데이터 갯수
- mean: 전체 데이터의 평균값
- std: 표준편차
- min: 최솟값
- max: 최댓값
- 25%: 25퍼센트에 해당하는 값
- 50%: 50퍼센트에 해당하는 값
- 75% : 75퍼센트에 해당하는 값
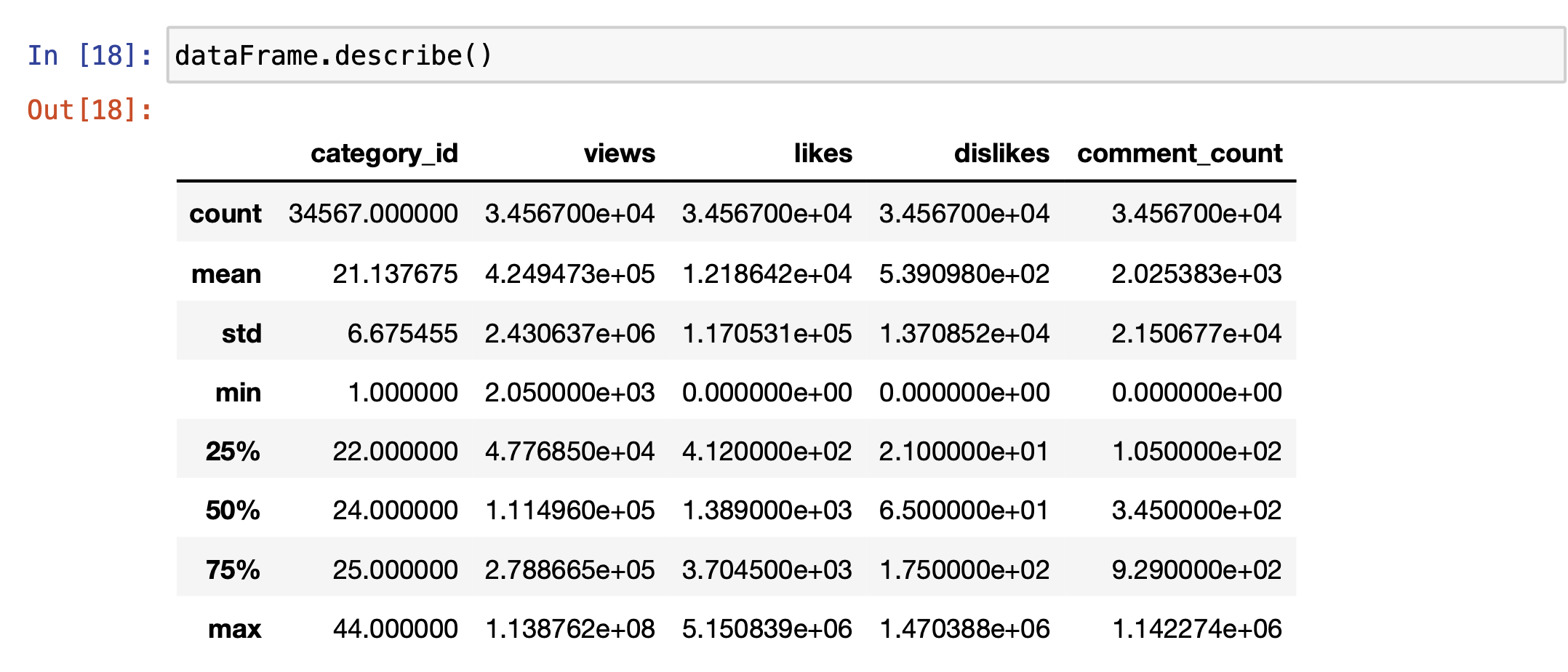
이 중, category_id는 identify를 위한 고유의 값이니까 의미 없는 데이터이므로 안봐도 됩니다.
4) 특정칼럼에 어떤 값들이 분포하고 있는가
dataFrame['칼럼이름'].value_counts()
dataFrame['칼럼이름'].value_counts() 로 특정 칼럼에 어떤 값이 분포하고 있는 지 알 수 있습니다.
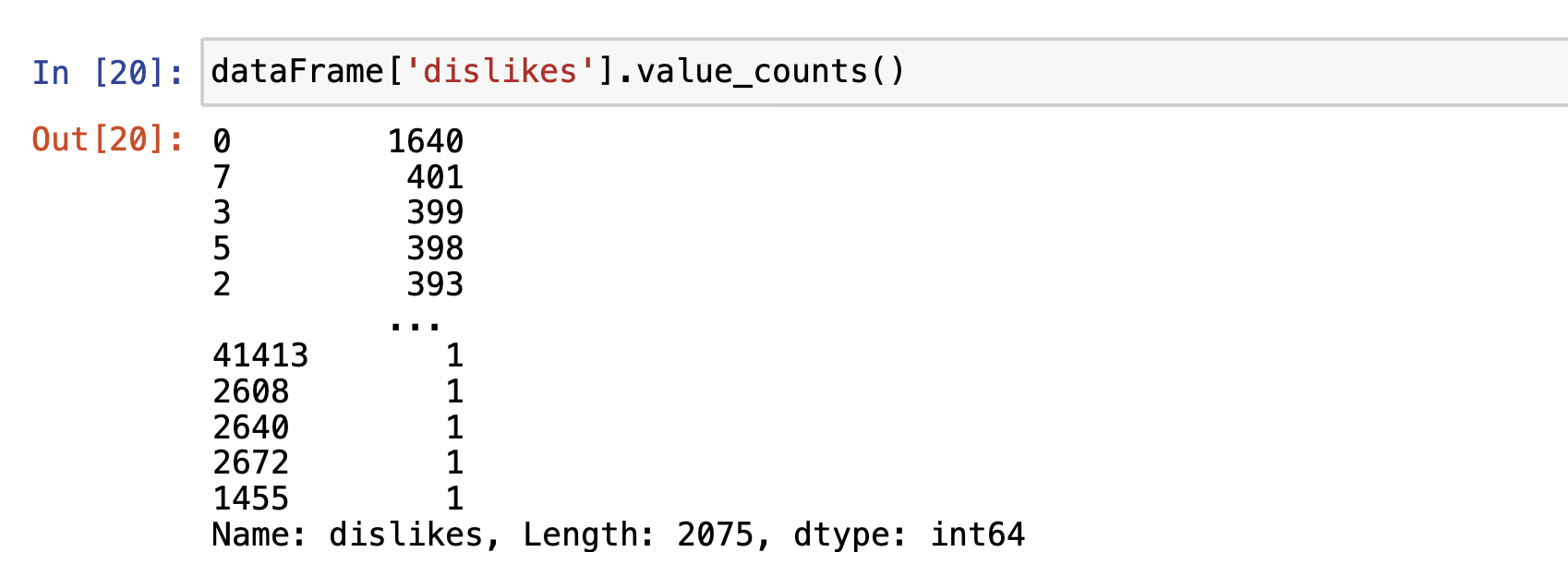
싫어요 갯수가 0인 데이터는 1640개,
7인 데이터는 401개,
3인 데이터는 399개....
이런식으로 해석할 수 있어요-!
'🐍 > Python' 카테고리의 다른 글
| [Python] 구글 Geocoding API 사용해보기 (3) | 2020.12.21 |
|---|---|
| [Python] 파이썬 타입힌트 (Type Hints) (0) | 2020.11.29 |
| [Python] Slack봇 만들기 - Incoming Webhooks bots (2) | 2020.03.26 |
| [BeautifulSoup] 영화관(CGV, 메가박스, 롯데시네마) 상영시간표 크롤링 (7) | 2020.03.16 |
| [BeautifulSoup] BeautifulSoup의 기능들 살펴보기 (0) | 2020.03.05 |
- Total
- Today
- Yesterday
- Flutter 로딩
- SerializerMethodField
- ribs
- ipad multitasking
- Flutter Spacer
- flutter 앱 출시
- Dart Factory
- 장고 Custom Management Command
- Flutter Clipboard
- Flutter getter setter
- 플러터 얼럿
- Django Firebase Cloud Messaging
- github actions
- METAL
- flutter build mode
- drf custom error
- DRF APIException
- Flutter Text Gradient
- 구글 Geocoding API
- Python Type Hint
- Django Heroku Scheduler
- Django FCM
- PencilKit
- flutter dynamic link
- cocoapod
- Sketch 누끼
- 플러터 싱글톤
- flutter deep link
- 장고 URL querystring
- Watch App for iOS App vs Watch App
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |